拈花云科基于 Apache DolphinScheduler 在文旅业态下的实践

作者|云科NearFar X Lab团队 左益、周志银、洪守伟、陈超、武超
一、导读
无锡拈花云科技服务有限公司(以下简称:拈花云科)是由拈花湾文旅和北京滴普科技共同孵化的文旅目的地数智化服务商。2022年底,拈花云科NearFar X Lab团队开始测试DolphinScheduler作为交付型项目和产品项目的任务调度工具。本文主要分享了拈花云科在任务调度工具的选择、迭代和实践过程中的经验,希望对大家有所启发。
二、业务背景
我们的服务对象主要是国内各个景区、景点,业务范围涵盖文旅行业的多个板块,如票务、交通、零售、住宿、餐饮、演绎、游乐、影院、KTV、租赁、服务、会务、康乐、康养、电商、客服、营销、分销、安防等。由于业务系统来源较多,多系统下的数据源类型差异化较大,所以在实施数据项目时我们需要能够支持多种数据来源(Mysql、Oracle、SqlServer、Hive、Excel……)的数据集成任务。同时根据大部分景区为国有化的特点,我们也需要具备能够提供私有化交付部署及SAAS化数据中台产品解决方案的双重服务支撑能力。
三、DolphinScheduler 调度系统选型过程
在团队成立之初为了快速构建MVP业务版本,我们沿用了团队同事之前用过的Kettle调度方案。该方案下通过Kettle完成可视化调度的配置及对于异构数据的集成任务,通过Python 调用HQL脚本完成基于Hive的传参数据计算。
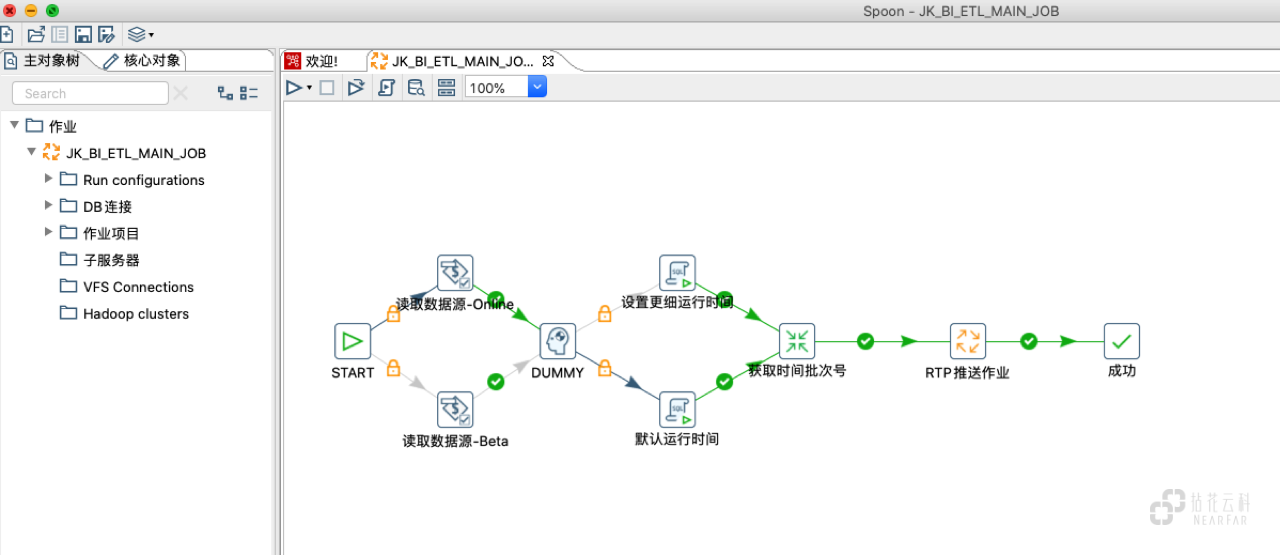
基于MVP的构建,我们也开始思考,在我们的整体中台架构下该需要一个什么样的调度系统,以及除了调度这件事本身我们还需要哪些功能和能力。带着这些问题我们开始整理自己的需求,以及每个需求下有什么样的产品可以适配。
调度系统需要支撑的应用场景
文旅业态下的数据使用场景与其它业态下的使用场景大体相同,主要分为以下四类:

调度系统需要支撑的项目类型
我们选择的调度系统需要同时具备实施类项目、SAAS产品两种需求下的数据中台支撑能力

基于以上需求我们进行了调度系统的选型对比。网上有非常多关于Oozie、Azkaban、Airflow、DolphinScheduler、Xxl-job、Kettle等调度选型的文章及介绍,在此不过多的展开他们的优缺点。我们觉得每个产品的设计都有它自身的考量,都有适用与不适用的场景。结合我们自身的使用需求最终我们选择了使用DolphinScheduler作为数据中台的调度平台。
主要原因如下:
- High Reliability(高可靠性)
高可靠性是我们看重的第一要点,因为不管是实施项目还是SAAS产品,只有系统稳定产品才可以正常运行。DolphinScheduler通过去中心化设计、原生 HA 任务队列支持、过载容错能力支持提供了高度稳健的环境。在我们半年的使用过程中也验证了其非常稳定。 - High Scalability:(高扩展性)
由于我们要支持实施项目/SAAS产品两种场景下的使用,DolphinScheduler的多租户支持很好的契合了SAAS场景下资源隔离的使用需求。同时其扩缩容能力、高度的调度任务上限(10万+)都能很好的支撑我们业务的扩展性需求。 - 丰富的数据集成能力
DolphinScheduler提供的任务类型已经远远涵盖了我们经常使用的任务类型(DataX、SeaTunnel的支持本身就涵盖了较多的Source2Target同步/推送场景)。 - 支持Kubernetes部署
上文提到在私有化的部署方式下客户的部署环境大不相同,对于实施团队来说,如果能够简单、高效、一致的完成部署则会极大的提高项目投递部署效率,同时也能减少很多因环境原因而产生的问题。 - 不仅仅是调度
在调研DolphinScheduler的过程中我们发现,除了调度本身这个环节,结合DCMM(数据管理能力成熟度评估模型)的国标8个能力域,DolphinScheduler在数据质量模块也做了很多实现,这无疑又命中了我们对于数据质量能力建设的需求。同时Apache DolphinScheduler的服务架构中还有AlertServer服务。作为整体数据中台方案来说后期完全可以将所有报警需求集成在Apache DolphinScheduler的报警服务中,避免多系统重复造轮子。从这些点考虑DolphinScheduler它不仅仅是一个调度工具而更像是一个数据开发平台。(期待随着社区的迭代会有更完整的生态实现) - 问题处理难度
DolphinScheduler社区非常的活跃,在加入DolphinScheduler社区群后每天都可以看到非常多的伙伴在交流关于Apache DolphinScheduler使用过程中的问题,社区人员也都积极的予以回复。同时Dolphinscheduler又是咱们国产开源软件,所以完全不必担心存在沟通上的障碍。
四、基于DolphinScheduler的项目实践
1、DolphinScheduler ON Kubernetes
DolphinScheduler支持多种部署方式:单机部署(Standalone)、伪集群部署(Pseudo-Cluster)、集群部署(Cluster)、Kubernetes部署(Kubernetes)。在项目实施的场景下由于客户提供的部署环境千变万化,我们需要一种稳定、快速、不挑环境的部署方式。Apache DolphinScheduler on K8S的部署方式很好的满足了我们的需求,此部署方式能极大的提高整体项目的部署效率及动态扩展性。
- Kubernetes是一个开源的容器编排平台,可以实现容器的自动化部署、扩缩容、服务发现、负载均衡,可以提高DolphinScheduler的可用性、可扩展性和可维护性
- Kubernetes可以支持多种存储类型,包括本地存储、网络存储和云,可以满足DolphinScheduler多节点共享持久化存储需求
- Kubernetes可以支持多种调度策略,包括亲和性、反亲和性、污点和容忍,可以优化DolphinScheduler的资源利用率,提高任务执行效率。
- Kubernetes可以支持多种监控和日志方案,包括Prometheus、Grafana、ELK等等,可以方便地对DolphinScheduler的运行状态和性能进行监控,分析和告警
在部署Apache DolphinScheduler on K8S 的过程中我们也曾遇到过一些问题,下面是我们总结的一些Kubernetes部署要点:
自定义镜像
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-alert-server:版本号
# 如果你想支持 MySQL 数据源
COPY ./mysql-connector-java-8.0.16.jar /opt/dolphinscheduler/libs
dolphinscheduler-api
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-api:版本号
# 如果你想支持 MySQL 数据源
COPY ./mysql-connector-java-8.0.16.jar /opt/dolphinscheduler/libs
# 如果你想支持 Oracle 数据源
COPY ./ojdbc8-19.9.0.0.jar /opt/dolphinscheduler/libs
dolphinscheduler-master
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-master:版本号
# 如果你想支持 MySQL 数据源
COPY ./mysql-connector-java-8.0.16.jar /opt/dolphinscheduler/libs
dolphinscheduler-tools
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-tools:版本号
# 如果你想支持 MySQL 数据源
COPY ./mysql-connector-java-8.0.16.jar /opt/dolphinscheduler/libs
dolphinscheduler-worker
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-worker:版本号
# 如果你想支持 MySQL 数据源
COPY ./mysql-connector-java-8.0.16.jar /opt/dolphinscheduler/libs
# 如果你想支持 Oracle 数据源
COPY ./ojdbc8-19.9.0.0.jar /opt/dolphinscheduler/libs
# 如果你想支持 hadoop 数据源
COPY ./hadoop-common-2.7.3.jar /opt/dolphinscheduler/libs
COPY ./hadoop-core-1.2.1.jar /opt/dolphinscheduler/libs
# 如果你想支持 hive 数据源
COPY ./hive-common.jar /opt/dolphinscheduler/libs
COPY ./hive-jdbc.jar /opt/dolphinscheduler/libs
COPY ./hive-metastore.jar /opt/dolphinscheduler/libs
COPY ./hive-serde.jar /opt/dolphinscheduler/libs
COPY ./hive-service.jar /opt/dolphinscheduler/libs
# 安装python3环境
RUN apt-get update && \
apt-get install -y --no-install-recommenApache DolphinScheduler curl && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && \
apt-get install -y --no-install-recommenApache DolphinScheduler libcurl4-openssl-dev libssl-dev && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && \
apt-get install -y --no-install-recommenApache DolphinScheduler python3 && \
rm -rf /var/lib/apt/lists/*
RUN apt-get update && \
apt-get install -y --no-install-recommenApache DolphinScheduler python3-pip && \
rm -rf /var/lib/apt/lists/*
# 安装dataX 并且解压缩
COPY ./datax.tar.gz /home
RUN tar -zxvf /home/datax.tar.gz -C /opt
配置文件修改
官方教程中的helm进行安装,在安装过程中需要修改源码中 "/deploy/kubernetes/dolphinscheduler/" 路径下的 "values.yaml,Chart.yaml" 里的相关镜像和版本(注:原配置没有指定持久化储存类,会使用默认的存储类,建议是修改并使用可多节点读写并且可以弹性扩展的,多节点读写便于worker节点共用同一套lib)
生产配置
- dolphinscheduler-api 3 副本(注:默认是 1副本,但是实际使用中发现,平台页面在使用过程中会有卡顿,增加副本数之后,会有明显改善)
- dolphinscheduler-alert 1副本
- dolphinscheduler-zookeeper 1副本
- dolphinscheduler-worker 3副本
- dolphinscheduler-master 3副本
k8s部署总结
采用k8s部署后,最大感受就是可排除环境干扰,快速扩展,迁移,部署,帮助我司实现了数据中台私有化中的调度标准化,该方案已在多个景区中进行快速落地并应用。
2、基于SQL脚本血缘的DolphinScheduler工作流自动化实现
项目背景
基于景区中各个业务系统(票务、营销、安防、酒店、商业、能耗、停车等)在景区机房下建设数据中台,完成以下应用需求:
- 满足各个业务部门日常的报表需求
- 支持各类大屏看板展示
- 为景区的管理层决策提供数据依据
技术选型
数据仓库:Doris
调度工具:DolphinScheduler 使用版本:3.0.0
版本管理:Gitlab
容器编排:Kubernete
处理流程
- 业务分析与指标确认:与业务部门沟通,了解业务需求和目标,明确数据指标的定义、计算逻辑和展示方式。
- 数据仓库分层和设计:根据数据仓库的四层架构(ODS、DWD、DWS、ADS),设计数据模型和表结构,规范命名和注释。
- 数据脚本开发:编写数据抽取、清洗、转换、加载等脚本,实现数据从源系统到目标表的流转和处理。
- 数据任务调度:入仓后的执行脚本通过血缘识别依赖自动录入DolphinScheduler形成工作流任务调度(设置任务依赖、触发条件、重试策略等参数)监控任务运行状态和日志。
- 数据输出和文档:输出标准指标库和相关文档,供BI、可视化报表等使用,同时编写数据开发文档,记录数据开发过程中的关键信息和问题。
下面介绍下我们根据SQL血缘识别自动生成Apache DolphinScheduler调度任务的实现过程:
在DolphinScheduler平台上开发数据调度工作流的过程中我们遇到一个问题:如果一个工作流下的任务量太多,在原有的UI界面中想通过界面方式完成配置更改以及血缘关系的建立等操作会非常不便捷。即便是通过任务定义去配置,当上百个任务同时需要配置依赖关系时也是一个不小的工作量开销而且还容易出错,后期的更新迭代也较为不便。
我们结合工作流下SQL任务本身的特点(数仓SQL任务是整体按照Apache DolphinScheduler、DWD、DWS、Apache DolphinScheduler 的计算流程进行计算,每个表对应一个Apache DolphinScheduler的Task既每个Task都会包含SourceTable及TargetTabe。通过这层关系我们就可以构建起完整的数仓任务血缘依赖)。基于以上想法我们实现了从数据脚本自动生成对应的工作流和任务的自动化方案:
- 数据入仓后的开发脚本以每个表单为单位对应生成一个TaskSQL脚本提交到git。
- 自动化工具生成工作流及任务前自动从git库中获取最新的数据脚本。
- 自动化工具拉取到最新代码后识别和分析所有数据脚本之间的血缘关系。
- 自动化工具通过血缘关系自动将所有的任务关联并组装到一个工作流中:每个任务执行完成后,会立即触发下游任务,最大化地利用服务器资源。
以下是该实现的核心代码:
sql解析
SqlParse是使用阿里的druid中的组件MySqlStatementParser
/**
* sql解析
* @param sqlStr
* @return
*/
public static Map<String, Set<String>> sqlParser(String sqlStr) {
List<String> sqlList = StrUtil.split(sqlStr, ";");
Map<String, Set<String>> map = new HashMap<>();
for (String sql : sqlList) {
if (StrUtil.isBlank(sql)) {
continue;
}
// 这里使用的时 mysql 解析
MySqlStatementParser parser = new MySqlStatementParser(sql);
SQLStatement sqlStatement = parser.parseStatement();
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
sqlStatement.accept(visitor);
Map<TableStat.Name, TableStat> tableStatMap = visitor.getTables();
for (Map.Entry<TableStat.Name, TableStat> tableStatEntry : tableStatMap.entrySet()) {
String name = tableStatEntry.getKey().getName();
// 这里的 value 有两种 Select(父级)、Insert(子级)
String value = tableStatEntry.getValue().toString();
if (map.containsKey(value)) {
map.get(value).add(name);
} else {
Set<String> list = new HashSet<>();
list.add(name);
map.put(value, list);
}
}
}
return map;
}
节点对象定义
/**
* 任务节点定义
*/
public class Apache DolphinSchedulerTaskNode implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 源表
*/
private List<String> sourceTableName = new ArrayList<>();
/**
* 目标表
*/
private String targetTableName;
/**
* 源sql
*/
private String sql;
/**
* 用sql做一个MD5签名
*/
private String md5;
/**
* 用sql名称
*/
private String name;
/**
* 任务code
*/
private Long taskCode;
...
}
/**
* 树型节点定义
*/
public class MyTreeNode extenApache DolphinScheduler Apache DolphinSchedulerTaskNode {
/**
* 添加一个子节点列表属性
*/
private List<MyTreeNode> children;
...
}
树型结构组装
/**
* 解析sql,并组装node
*
* @param files
* @return
*/
private static List<MyTreeNode> treeNodeProcess(List<File> files) {
List<MyTreeNode> sourceList = new ArrayList<>();
for (File sqlFile : files) {
// 1 取出里面的 sql 脚本内容
String sql = FileUtil.readUtf8String(sqlFile);
// 2 解析里面的脚本内容
Map<String, Set<String>> map = null;
try {
// 血缘解析
map = AutoCreateTask.sqlParser(sql);
} catch (Exception e) {
log.error(" table-parser error: {}", sqlFile.getPath());
}
// 3 将每一个sql的 source , target 解析出来
if (ObjectUtil.isNotNull(map)) {
MyTreeNode treeNode = new MyTreeNode();
treeNode.setName(sqlFile.getName());
if (map.containsKey("Select")) {
Set<String> select = map.get("Select");
treeNode.setSourceTableName(new ArrayList<>(select));
}
treeNode.setSql(sql);
if (map.containsKey("Insert")) {
Set<String> insert = map.get("Insert");
treeNode.setTargetTableName(new ArrayList<>(insert).get(0));
}
sourceList.add(treeNode);
}
}
// 将sql按照 source , target 组成 树状结构
return TreeUtil.getTree(sourceList);
}
/**
* 组成树状结构
* @param sourceList
* @return
*/
public static List<MyTreeNode> getTree(List<MyTreeNode> sourceList) {
Map<String, Set<MyTreeNode>> sourceMap = new HashMap<>();
Map<String, Set<MyTreeNode>> targetMap = new HashMap<>();
for (MyTreeNode node : sourceList) {
//源表Map
List<String> subSourceTableList = node.getSourceTableName();
if (IterUtil.isNotEmpty(subSourceTableList)) {
for (String subSourceTable : subSourceTableList) {
if (sourceMap.containsKey(subSourceTable)) {
sourceMap.get(subSourceTable).add(node);
} else {
Set<MyTreeNode> nodeSet = new HashSet<>();
nodeSet.add(node);
sourceMap.put(subSourceTable, nodeSet);
}
}
}
//目标表Map
String targetTableName = node.getTargetTableName();
if (targetMap.containsKey(targetTableName)) {
targetMap.get(targetTableName).add(node);
} else {
Set<MyTreeNode> nodeSet = new HashSet<>();
nodeSet.add(node);
targetMap.put(targetTableName, nodeSet);
}
}
//创建一个列表,用于存储根节点
List<MyTreeNode> rootList = new ArrayList<>();
for (MyTreeNode node : sourceList) {
// 将子节点处理好
String targetTableName = node.getTargetTableName();
if (sourceMap.containsKey(targetTableName)) {
List<MyTreeNode> childrenList = node.getChildren();
if (IterUtil.isEmpty(childrenList)) {
childrenList = new ArrayList<>();
node.setChildren(childrenList);
}
childrenList.addAll(sourceMap.get(targetTableName));
}
List<String> subSourceTableList = node.getSourceTableName();
boolean isRoot = true;
for (String subSourceTable : subSourceTableList) {
if (targetMap.containsKey(subSourceTable)) {
isRoot = false;
break;
}
}
if (isRoot) {
rootList.add(node);
}
}
return rootList;
}
部分效果图展示:
自动化生成的任务定义
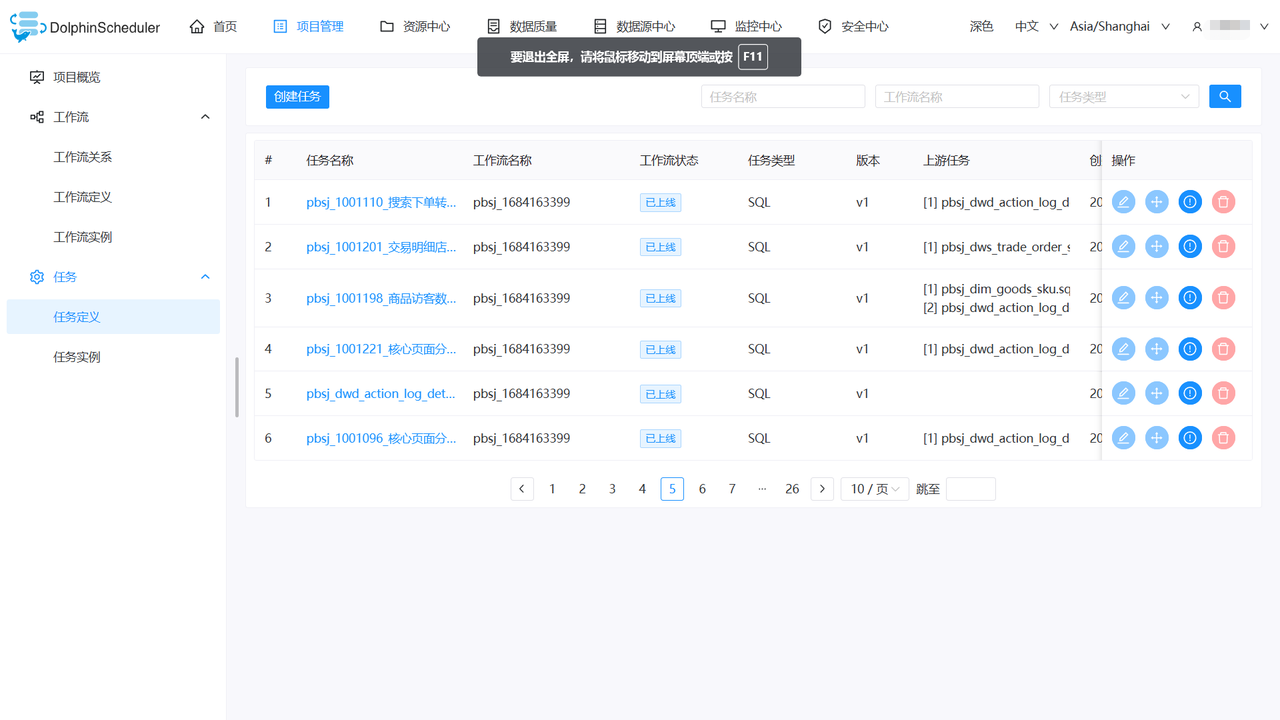
自动化生成的工作流定义图

增量运行结果

自动化实现总结
- 数仓调度任务的秒级上线与切换
通过该方式将数仓开发与DolphinScheduler解耦,实现了整体数据调度任务的秒级上线与切换。这样,我们可以快速复制标品化数据建模,极大地简化了实施的难度。 - 血缘进行的任务关联与生成
通过血缘进行的任务关联与生成,大大提升了整体的资源利用率,也减少了人工的投入和成本。 - 血缘监控和管理
通过血缘监控和管理,可以帮助我们及时发现和纠正任务执行过程中的问题和错误,保证数据质量和准确性。
五、未来规划
- 离在线统一调度 :实现基于Apache SeaTunnel的离线与实时数据同步调度,使得两个场景在一个平台完成。
- 应用基线管理:根据各任务的上下游依赖构建数据应用基线,并监控各目标任务及其依赖任务是否按时成功运行,以确保目标任务的准时产出。
- 任务指标监控:支持实时查看每个组件的指标,例如输入记录数、输出记录数和执行时间等。
- 数据血缘关系:上报数据源、目标表、字段等信息,构建数据血缘关系图,方便追溯数据的来源和影响。
- 资源文件版本管理:支持资源文件等的简单多版本管理,可以查看历史版本、回滚到指定版本等。
六、总结与致谢
- 通过使用DolphinScheduler替换原有的调度工具,使得数据开发运维实现了平台统一化。基于Apache DolphinScheduler提供的强大集成扩展插件能力大大提升了数据集成与数据开发的效率。
- DolphinScheduler自带的告警管理功能非常全面。配合此功能我们建立了运维值班制度以及微信告警通知的功能。故障发生时,运维人员可以第一时间收到报警通知,有效提高了故障的感知能力。
- 基于DolphinScheduler调度技术方案在多个项目中的优异表现,使得我们更好的推动了公司的数据驱动战略。从实践中沉淀出公司的数据实施SOP,为各个客户、业务部门提供了及时、准确、全面的数据分析和决策支持。
- 我们第一次部署时使用的是3.0.0 版本。目前社区已经发布了 3.1.7 迭代速度非常快。如果你们的项目正在选型调度工具,我们强烈建议使用DolphinScheduler。加入社区进群会有非常多的前辈、大佬带你起飞。DolphinScheduler 值得大力推荐,希望大家都能从中受益,祝愿DolphinScheduler生态越来越繁荣,越来越好!
本文由 白鲸开源 提供发布支持!
热门相关:恭喜你被逮捕了 前任无双 民国之文豪崛起 半仙 回眸医笑,冷王的神秘嫡妃