【爬虫案例】用Python爬大麦网任意城市的近期演出活动!
一、爬取目标
大家好,我是@马哥python说 ,一枚10年程序猿。
今天分享一期python爬虫案例,爬取目标是大麦网近期演出活动:- 大麦搜索
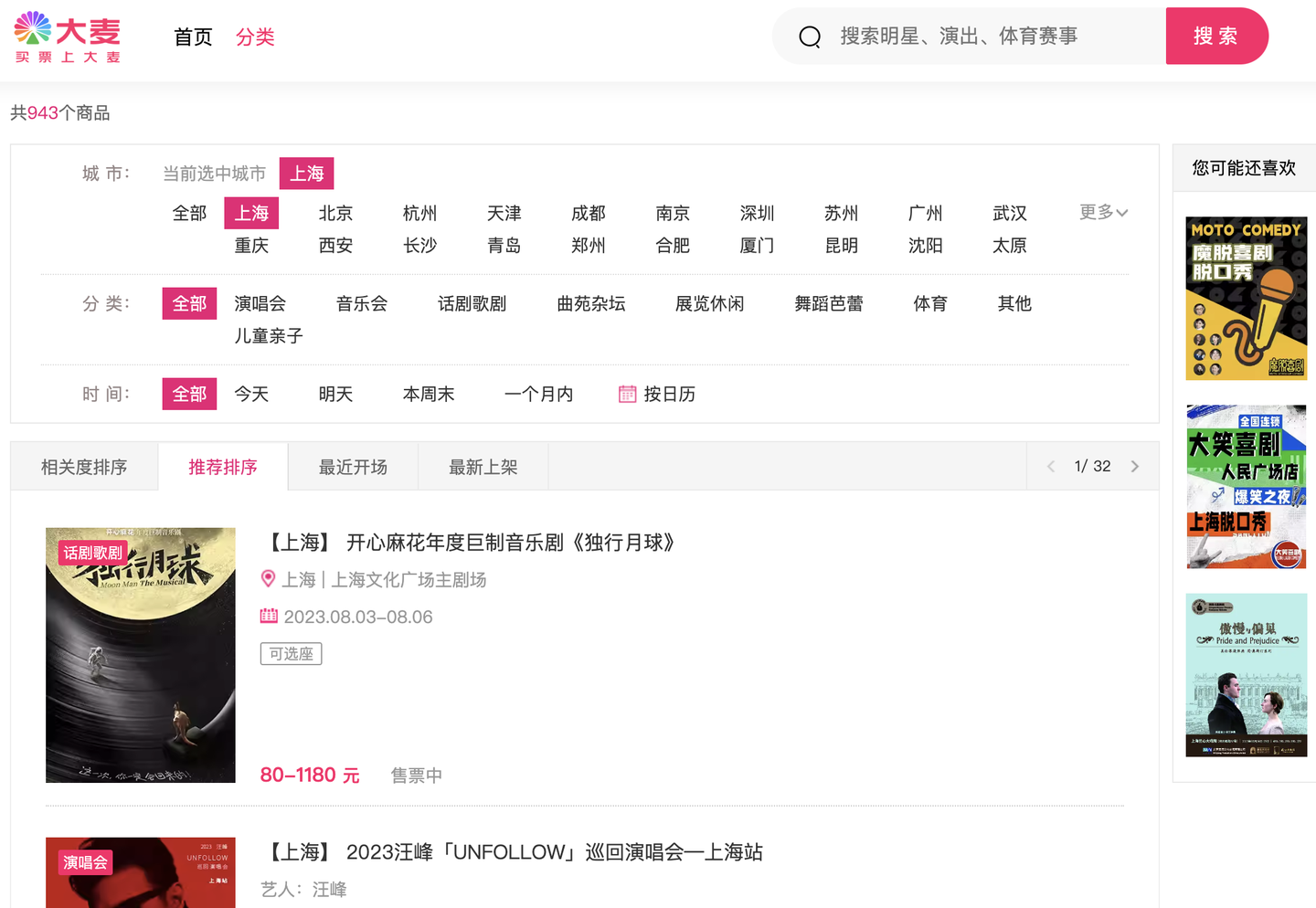
二、展示爬取结果
爬取结果截图:

含10个字段:
页码,演出标题,链接地址,演出时间,演出城市,演出地点,售价,演出类别,演出子类别,售票状态。
演示视频:【Python爬虫演示】爬取大麦网任意城市的近期演出!
以上。
三、讲解代码
首先,导入需要用到的库:
import pandas as pd
import requests
import os
import datetime
from time import sleep
import random
定义一个请求头:
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299',
'Cookie': '换成自己的cookie',
'X-Xsrf-Token': '7d065ac9-b924-4c14-869a-ab599b571244',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh;q=0.8,zh-CN;q=0.7',
'Bx-V': '2.5.0',
'Referer': 'https://search.damai.cn/search.htm?spm=a2oeg.home.category.ditem_0.591b23e1HxE6Vj&ctl=%E6%BC%94%E5%94%B1%E4%BC%9A&order=1&cty=%E6%88%90%E9%83%BD',
'Sec-Ch-Ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': "macOS",
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
}
其中,cookie的获取方式如下:
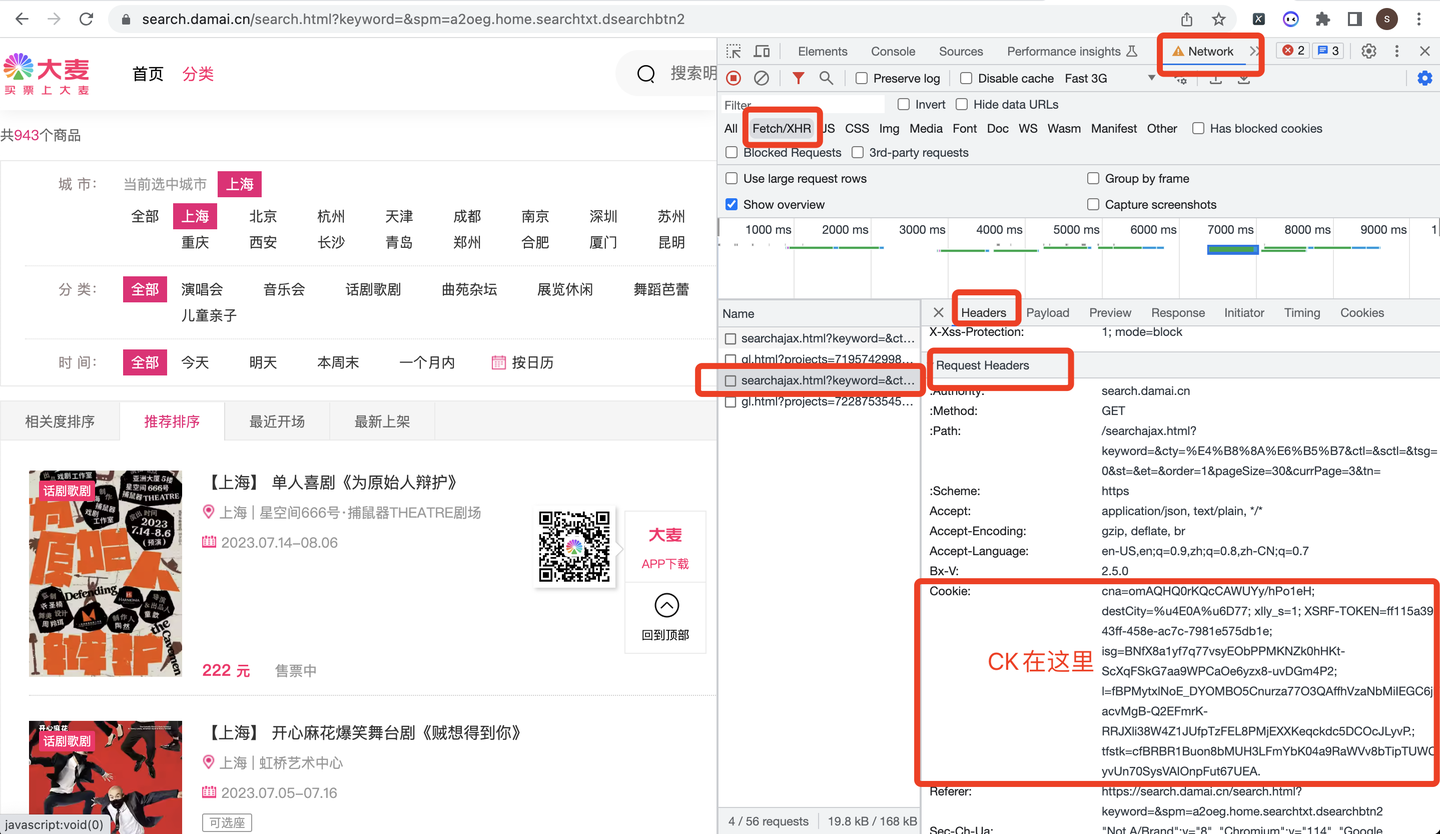
定义请求地址url:
# 请求地址
url = 'https://search.damai.cn/searchajax.html'
定义请求参数params,从PayLoad中获取:

发送请求,并且用json格式解析数据:
# 发送请求
r = requests.get(url, headers=headers, params=params)
# 解析数据
json_data = r.json()
以"演出标题"字段为例:
for data in json_data['pageData']['resultData']:
# 演出标题
title = data['nameNoHtml']
title_list.append(title)
print('演出标题:', title)
其他字段同理,不再赘述。
最后是保存到csv文件:
df = pd.DataFrame(
{
'页码': page,
'演出标题': title_list,
'链接地址': href_list,
'演出时间': time_list,
'演出城市': city_list,
'演出地点': loc_list,
'售价': price_list,
'演出类别': category_list,
'演出子类别': subcategory_list,
'售票状态': status_list,
}
)
# 保存到csv文件
df.to_csv(result_file, encoding='utf_8_sig', mode='a+', index=False, header=header)
其中,encoding参数设置为utf_8_sig,目的是防止csv文件产生乱码,不便读取。
整个代码中,还含有:设置sleep随机等待、判断循环停止条件、防止多次写入表头、用户input输入过滤条件、往csv文件名添加时间戳等功能,篇幅有限,详细请见原始代码。
四、同步视频
代码演示视频:
【Python爬虫演示】爬取大麦网任意城市的近期演出!
五、附完整源码
完整源码获取:【爬虫案例】用Python爬大麦网任意城市演出活动
我是@马哥python说 ,持续分享python源码干货中!