Linux工作原理7系统配置:日志、系统时间、批处理作业和用户
7 系统配置:日志、系统时间、批处理作业和用户
当你第一次进入 /etc 目录查看系统配置时,可能会感到有些不知所措。好在虽然你看到的大多数文件都会在一定程度上影响系统的运行,但只有少数文件是基本文件。
本章将介绍系统中使第 4 章中讨论的基础架构可供用户空间软件使用的部分,这些软件通常与我们交互,例如第 2 章中介绍的工具。我们将特别关注以下内容:
- 系统日志
- 系统库访问以获取服务器和用户信息的配置文件
- 系统启动时运行的一些选定的服务器程序(有时称为守护进程,可用于调整服务器程序和配置文件的配置实用程序
- 时间配置
- 定期任务调度
systemd 的广泛使用减少了典型 Linux 系统中基本、独立守护进程的数量。系统日志(syslogd)守护进程就是一个例子,它的功能现在主要由 systemd 内置的一个守护进程(journald)提供。但仍有一些传统守护进程保留了下来,如 crond 和 atd。
与前几章一样,本章几乎没有网络方面的内容,因为网络是系统的一个独立构件。在第 9 章中,你将看到网络的作用。
7.1 系统日志
大多数系统程序都会将诊断输出作为信息写入 syslog 服务。传统的 syslogd 守护进程通过等待消息并在收到消息后将其发送到适当的通道(如文件或数据库)来执行这项服务。在大多数现代系统中,大部分工作由 journald(systemd 自带)完成。虽然我们在本书中将重点讨论 journald,但我们也会涉及传统系统日志的许多方面。
系统日志是系统中最重要的部分之一。当出现问题而不知从何入手时,查看日志总是明智之举。如果使用 journald,则可以使用 journalctl 命令来查看日志,我们将在第 7.1.2 节介绍该命令。在旧系统上,则需要检查文件本身。无论哪种情况,日志信息都是这样的
Aug 19 17:59:48 duplex sshd[484]: Server listening on 0.0.0.0 port 22.
日志信息通常包含进程名称、进程 ID 和时间戳等重要信息。此外还有两个字段:facility(一般类别)和 severity(信息的紧急程度)。稍后我们将详细讨论这两个字段。
由于新旧软件组件的组合各不相同,在 Linux 系统中理解日志记录可能有些难度。一些发行版(如 Fedora)已改用仅日志记录的默认设置,而另一些发行版则在运行 journald 的同时运行旧版 syslogd(如 rsyslogd)。较早的发行版和某些专用系统可能根本不使用 systemd,而只使用其中一个 syslogd 版本。此外,有些软件系统会完全绕过标准化日志,自己编写日志。
7.1.1 检查日志设置
您应该检查自己的系统,看看安装了何种日志记录。方法如下:
- 检查 journald,如果运行的是 systemd,则几乎肯定安装了 journald。虽然可以在进程列表中查找 journald,但最简单的方法还是运行 journalctl。如果 journald 在系统中处于活动状态,你就会看到日志信息的分页列表。
- 检查 rsyslogd。在进程列表中查找 rsyslogd,并查看 /etc/rsyslog.conf。如果没有 rsyslogd,请查看 syslog-ng(syslogd 的另一个版本),查找名为 /etc/syslog-ng 的目录。
- 继续在 /var/log 中查找日志文件。如果使用的是 syslogd 版本,该目录应该包含许多文件,其中大部分由 syslog 守护进程创建。不过,这里也会有一些由其他服务维护的文件,比如 wtmp 和 lastlog,它们是 last 和 lastlog 等实用程序访问的日志文件,用于获取登录记录。
此外,/var/log 中可能还有更多包含日志的子目录。这些日志几乎总是来自其他服务。其中的 /var/log/journal 就是 journald 存储其(二进制)日志文件的地方。
参考资料
- 软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
- 本文涉及的python测试开发库 谢谢点赞! https://github.com/china-testing/python_cn_resouce
- python精品书籍下载 https://github.com/china-testing/python_cn_resouce/blob/main/python_good_books.md
- Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
7.1.2 搜索和监控日志
除非系统中没有 journald,或要搜索由其他工具维护的日志文件,否则都要查看日志。在没有参数的情况下,journalctl 访问工具就像消防水龙头,提供日志中的所有信息,从最旧的开始(就像它们在日志文件中一样)。值得庆幸的是,journalctl 默认使用 less 等寻呼机来显示消息,因此你的终端不会被淹没。你可以使用日志记录器搜索信息,也可以用 journalctl -r 来反转信息的时间顺序,但还有更好的方法来查找日志。
注意:要完全访问日志信息,需要以 root 或 adm 或 systemd-journal 组用户身份运行 journalctl。大多数发行版的默认用户都有访问权限。
一般来说,只需在命令行中添加日志的个别字段,就能搜索日志信息;例如,运行 journalctl _PID=8792 搜索来自进程 ID 8792 的日志信息。不过,最强大的过滤功能更具有通用性。如果需要多个条件,可以指定一个或多个。
- 按时间过滤
在缩小特定时间范围方面,-S(自)选项是最有用的选项之一。下面是一个最简单有效的使用示例:
$ journalctl -S -4h
$ journalctl -S 06:00:00
$ journalctl -S 2020-01-14
$ journalctl -S "2020-01-14 14:30:00
-4h 部分看起来像一个选项,但实际上是一个时间规范,告诉 journalctl 在当前时区搜索过去四小时内的邮件。你也可以使用特定日期和/或时间的组合:
-U(直到)选项的作用与此相同,它指定了 journalctl 检索信息的截止时间。不过,这个选项通常没那么有用,因为你通常会翻页或搜索信息,直到找到需要的内容,然后退出。
- 按单元过滤
另一种快速有效的获取相关日志的方法是按 systemd 单元过滤。你可以使用 -u 选项这样做:
$ journalctl -u cron.service
按单元过滤时,通常可以省略单元类型(本例中为.service)。
如果不知道特定单元的名称,可尝试使用此命令列出日志中的所有单元:
journalctl -F _SYSTEMD_UNIT
选项 -F 显示日志中特定字段的所有值。
- 查找字段
有时,你只需知道要搜索哪个字段。您可以按如下方式列出所有可用字段:
$ journalctl -N
任何以下划线开头的字段(如上例中的 _SYSTEMD_UNIT)都是受信任字段;发送报文的客户端不能更改这些字段。
- 文本过滤
搜索日志文件的经典方法是在所有日志文件中运行 grep,希望在文件中找到相关行或可能存在更多信息的位置。同样,你也可以使用 -g 选项,通过正则表达式搜索日志信息,如本例所示,它会返回包含 kernel 的信息,然后是内存:
journalctl -g 'kernel.*memory'
遗憾的是,用这种方法搜索日志时,只能得到与表达式匹配的信息。通常,重要信息可能就在时间附近。试着从匹配信息中找出时间戳,然后运行 journalctl -S,查看同一时间有哪些信息。
注意:-g选项要求使用特定库构建 journalctl。某些发行版不包含支持 -g 的版本。
- 按启动过滤
通常情况下,你会发现自己在查看日志时,会看到机器启动时或宕机(重启)前的信息。只需一次启动,从机器启动到停止,就能轻松获取信息。例如,如果要查找当前启动的开始时间,只需使用 -b 选项即可:
journalctl -g 'kernel.*memory'
也可以添加偏移量,例如,要从上一次启动开始,偏移量为-1。
$ journalctl -b -1
注意
结合 -b 和 -r(反向)选项,可以快速检查机器是否在最后一个周期干净利落地关机。试一试;如果输出与此处示例相似,则说明关机是干净的:
$ journalctl -r -b -1
-- Logs begin at Wed 2019-04-03 12:29:31 EDT, end at Fri 2019-08-02 19:10:14 EDT. --
Jul 18 12:19:52 mymachine systemd-journald[602]: Journal stopped
Jul 18 12:19:52 mymachine systemd-shutdown[1]: Sending SIGTERM to remaining processes...
Jul 18 12:19:51 mymachine systemd-shutdown[1]: Syncing filesystems and block devices.
你也可以通过 IDs 来查看引导,而不是像 -1 这样的偏移量。运行以下命令获取启动 ID:
$ journalctl --list-boots
-1 e598bd09e5c046838012ba61075dccbb Fri 2019-03-22 17:20:01 EDT—Fri 2019-04-12 08:13:52 EDT
0 5696e69b1c0b42d58b9c57c31d8c89cc Fri 2019-04-12 08:15:39 EDT—Fri 2019-08-02 19:17:01 EDT
最后,你可以使用 journalctl -k 显示内核信息(无论是否选择特定引导)。
- 按严重性/优先级过滤
有些程序会产生大量诊断信息,从而掩盖重要日志。通过在 -p 选项中指定一个介于 0(最重要)和 7(最不重要)之间的值,可以按严重程度过滤日志。例如,要获取 0 至 3 级的日志,请运行
$ journalctl --list-boots
-1 e598bd09e5c046838012ba61075dccbb Fri 2019-03-22 17:20:01 EDT—Fri 2019-04-12 08:13:52 EDT
0 5696e69b1c0b42d58b9c57c31d8c89cc Fri 2019-04-12 08:15:39 EDT—Fri 2019-08-02 19:17:01 EDT
如果只想要一组特定严重性级别的日志,请使用 ... range 语法:
$ journalctl -p 2..3
按严重性过滤听起来可以节省很多时间,但可能用处不大。大多数应用程序默认情况下都不会生成大量信息数据,不过有些应用程序会提供配置选项来启用更详细的日志记录。
- 简单的日志监控
监控日志的一种传统方法是在日志文件中使用 tail -f 或 less follow 模式 (less +F),查看系统日志记录器发送的信息。这并不是一种非常有效的常规系统监控方法(太容易遗漏某些内容),但在试图查找问题或实时仔细查看启动和运行情况时,它对检查服务非常有用。
由于 journald 不使用纯文本文件,因此使用 tail -f 并不奏效;相反,可以使用 journalctl 的 -f 选项,在日志到达时打印日志,效果与此相同:
$ journalctl -f
这种简单的调用足以满足大多数需求。不过,如果您的系统有大量与您的需求无关的日志信息,您可能需要添加前面提到的一些过滤选项。
7.1.3 日志文件轮换
使用 syslog 守护进程时,系统记录的任何日志信息都会进入日志文件,这意味着需要偶尔删除旧信息,以免它们最终占用所有存储空间。不同的发行版有不同的方法,但大多数都使用 logrotate 实用程序。
这种机制被称为日志轮转。由于传统的文本日志文件在开头包含最旧的信息,在结尾包含最新的信息,因此很难只删除文件中的旧信息来释放空间。相反,由 logrotate 维护的日志会被分成很多块。
例如,在 /var/log 中有一个名为 auth.log 的日志文件,其中包含最新的日志信息。然后是 auth.log.1、auth.log.2 和 auth.log.3,每个文件都包含逐渐变旧的数据。当 logrotate 认为是时候删除一些旧数据时,它会这样 “轮换 ”这些文件:
- 删除最老的文件 auth.log.3。
- 将 auth.log.2 重命名为 auth.log.3。
- 将 auth.log.1 重命名为 auth.log.2。
- 将 auth.log 重命名为 auth.log.1。
不同发行版的名称和一些细节有所不同。例如,在 Ubuntu 配置中,logrotate 会压缩从 “1 ”位置移动到 “2 ”位置的文件,因此在上例中,会有 auth.log.2.gz 和 auth.log.3.gz。在其他发行版中,logrotate 会用日期后缀重命名日志文件,例如 -20200529。这种方案的一个优点是更容易找到特定时间的日志文件。
你可能想知道,如果 logrotate 在另一个实用程序(如 rsyslogd)想要添加到日志文件的同时执行旋转,会发生什么情况。例如,日志程序打开日志文件进行写入,但在 logrotate 执行重命名之前没有关闭。在这种有点不寻常的情况下,日志信息会被成功写入,因为在 Linux 中,文件一旦打开,I/O 系统就无法知道它被重命名了。但要注意的是,信息出现在的文件将是带有新名称的文件,如 auth.log.1。
如果 logrotate 在日志程序尝试打开文件之前已经重命名了文件,则 open() 系统调用会创建一个新的日志文件(如 auth.log),就像 logrotate 未运行时一样。
7.1.4 日志维护
存储在 /var/log/journal 中的日志不需要轮换,因为 journald 本身可以识别并删除旧信息。与传统的日志管理不同,journald 通常根据日志文件系统的剩余空间、日志占文件系统的百分比以及日志的最大大小来决定是否删除信息。日志管理还有其他选项,如日志信息的最大允许年龄。有关默认设置和其他设置的说明,请参阅 journald.conf(5) 手册。
7.1.5 深入了解系统日志
在了解了 syslog 和日志的部分操作细节之后,现在是时候退一步,看看日志为何以及如何以这种方式运行。本讨论更偏重理论而非实践;您可以轻松跳到书中的下一个主题。
20 世纪 80 年代,一个缺口开始出现: Unix 服务器需要一种记录诊断信息的方法,但当时还没有这样做的标准。当 syslog 与 sendmail 电子邮件服务器一起出现时,其他服务的开发者都很乐意采用它。RFC 3164 描述了 syslog 的演变过程。
其机制相当简单。传统的 syslogd 监听并等待 Unix 域套接字 /dev/log 上的信息。syslogd 的另一个强大功能是,除了 /dev/log 之外,它还能监听网络套接字,使客户端机器能通过网络发送消息。
这样就可以将整个网络的所有 syslog 消息整合到一个日志服务器上,因此 syslog 深受网络管理员的欢迎。许多网络设备(如路由器和嵌入式设备)都可以充当 syslog 客户端,向服务器发送诊断信息。
Syslog 具有经典的客户端-服务器架构,包括自己的协议(目前在 RFC 5424 中定义)。不过,该协议并不总是标准的,早期的版本除了一些基本的结构外,并没有太多其他的结构。使用 syslog 的程序员需要为自己的应用程序设计一种描述性的、清晰简短的日志信息格式。随着时间的推移,该协议在增加新功能的同时,也尽可能保持向后兼容性。
- 设施、严重性和其他字段
由于 syslog 会将不同类型的信息从不同的服务发送到不同的目的地,因此它需要一种方法来对每条信息进行分类。传统的方法是使用通常(但不总是)包含在报文中的设施和严重性编码值。除了文件输出外,即使是非常老的 syslogd 版本,也能根据消息的设施和严重性将重要消息发送到控制台或直接发送给特定的登录用户--这是早期的系统监控工具。
设施是一种通用的服务类别,用于识别发送消息的对象。设施包括服务和系统组件,如内核、邮件系统和打印机。
严重性是日志信息的紧急程度。共有八个级别,从 0 到 7。它们通常用名称来表示,不过名称并不一致,在不同的实现中也有不同:
| 0: emerg | 4: warning |
|---|---|
| 1: alert | 5: notice |
| 2: crit | 6: info |
| 3: err | 7: debug |
设施和严重性共同构成优先级,在系统日志协议中打包为一个数字。您可以在 RFC 5424 中阅读有关这些字段的所有信息,在 syslog(3) 手册页中了解如何在应用程序中指定它们,在 rsyslog.conf(5) 手册页中了解如何匹配它们。不过,在 journald 世界中,严重性被称为优先级(例如,当运行 journalctl -o json 以获取机器可读的日志输出时),将它们转换为 journald 时可能会遇到一些困惑。
不幸的是,当你开始研究协议中优先级部分的细节时,你会发现它跟不上操作系统其他部分的变化和要求。严重性定义仍然保持良好,但可用的设施都是硬连接的,包括 UUCP 等很少使用的服务,而且无法定义新的服务(只有一些通用的 local0 至 local7 插槽)。
我们已经讨论过日志数据中的一些其他字段,但 RFC 5424 还包括结构化数据的规定,即应用程序程序员可用于定义自己字段的任意键值对集。虽然这些数据可以通过一些额外工作与 journald 配合使用,但将它们发送到其他类型的数据库更为常见。
- Syslog 与 journald 的关系
journald 在某些系统上已经完全取代了 syslog,你可能会问为什么其他系统上还保留着 syslog。主要有两个原因:Syslog 有一个定义明确的方法来汇总多台机器上的日志。如果日志只在一台机器上,监控日志就容易得多;syslog 的版本(如 rsyslogd)是模块化的,能够输出到许多不同的格式和数据库(包括日志格式)。这使它们更容易连接到分析和监控工具。
相比之下,journald 强调将单台机器的日志输出收集整理成单一格式。
当你想做更复杂的事情时,journald 将日志输入不同日志记录器的功能提供了高度的通用性。尤其是当你考虑到 systemd 可以收集服务器单元的输出并将其发送到 journald 时,你可以访问比应用程序发送到 syslog 更多的日志数据。
- 关于日志记录的最后说明
Linux 系统上的日志记录在其发展历程中发生了巨大变化,而且几乎可以肯定的是,它还将继续发展。目前,在单台机器上收集、存储和检索日志的过程已经明确定义,但日志记录的其他方面还没有标准化。
首先,当你想在机器网络上汇总和存储日志时,会有一系列令人眼花缭乱的选择。集中式日志服务器不再是简单地将日志存储在文本文件中,现在可以将日志存入数据库,而集中式服务器本身通常也会被互联网服务所取代。
其次,日志的使用性质也发生了变化。曾几何时,日志并不被视为 “真实 ”数据;日志的主要用途是(人工)管理员在出错时可以读取的资源。然而,随着应用程序变得越来越复杂,日志记录的需求也随之增长。这些新需求包括搜索、提取、显示和分析日志中数据的能力。虽然我们有很多方法可以在数据库中存储日志,但在应用程序中使用日志的工具仍处于起步阶段。
最后,还要确保日志的可信度。最初的 syslog 没有任何认证可言;你只需相信发送日志的应用程序和/或机器说的是实话。此外,日志没有加密,容易被网络窥探。对于安全性要求较高的网络来说,这是一个严重的风险。当代的系统日志服务器拥有加密日志信息和验证日志来源机器的标准方法。然而,当你深入到单个应用程序时,情况就不那么明朗了。例如,如何确定自称是网络服务器的东西实际上就是网络服务器?
我们将在本章稍后部分探讨一些高级身份验证主题。现在,我们先来了解一下系统中配置文件的基本组织结构。
7.2 /etc 的结构
Linux 系统上的大多数系统配置文件都在 /etc 中。历史上,每个程序或系统服务都有一个或多个配置文件,由于 Unix 系统中的组件数量庞大,/etc 文件很快就会堆积起来。
这种方法有两个问题:很难在运行中的系统上找到特定的配置文件,而且很难维护这样配置的系统。例如,如果你想更改 sudo 配置,就必须编辑 /etc/sudoers。但在更改之后,发行版的升级可能会覆盖 /etc 中的所有内容,从而抹掉你的自定义配置。
多年来的趋势是将系统配置文件放在 /etc 下的子目录中,正如你已经看到的 systemd,它使用 /etc/systemd。虽然 /etc 中仍有一些单独的配置文件,但如果运行 ls -F /etc,就会发现其中的大部分项目现在都是子目录。
为了解决覆盖配置文件的问题,你现在可以将自定义配置放在配置子目录中的单独文件中,例如 /etc/grub.d 中的文件。
/etc 中有哪些配置文件?基本原则是,单台机器的自定义配置,如用户信息(/etc/passwd)和网络详细信息(/etc/network),应放入 /etc。不过,一般的应用细节,如发行版的用户界面默认设置,则不属于 /etc。不需要定制的系统默认配置文件通常也放在其他地方,比如 /usr/lib/systemd 中的预打包 systemd 单元文件。
我们已经了解了一些与启动相关的配置文件。下面我们继续来看看如何在系统中配置用户。
7.3 用户管理文件
Unix 系统允许多个独立用户。在内核层,用户只是一个数字(用户 ID),但由于记住一个名字比记住一个数字要容易得多,所以在管理 Linux 时,通常使用用户名(或登录名)。用户名只存在于用户空间,因此任何使用用户名的程序在与内核对话时,都需要找到其对应的用户 ID。
7.3.1 /etc/passwd文件
明文文件 /etc/passwd 将用户名映射到用户 ID。它看起来像清单 7-1。
root:x:0:0:Superuser:/root:/bin/sh
daemon:*:1:1:daemon:/usr/sbin:/bin/sh
bin:*:2:2:bin:/bin:/bin/sh
sys:*:3:3:sys:/dev:/bin/sh
nobody:*:65534:65534:nobody:/home:/bin/false
juser:x:3119:1000:J. Random User:/home/juser:/bin/bash
beazley:x:143:1000:David Beazley:/home/beazley:/bin/bash
每一行代表一个用户,有七个字段,以冒号分隔。第一行是用户名。接下来是用户的加密密码,或者至少是曾经的密码字段。在大多数 Linux 系统中,密码实际上不再存储在 passwd 文件中,而是存储在影子文件中(参见第 7.3.3 节)。影子文件的格式与 passwd 类似,但普通用户没有读取影子文件的权限。passwd 或 shadow 文件中的第二个字段是加密密码,看起来像一堆无法读取的垃圾,如 d1CVEWiB/oppc。Unix 密码从不以明文存储;事实上,该字段并不是密码本身,而是密码的派生词。在大多数情况下,从该字段中获取原始密码异常困难(假设密码不容易猜到)。
第二个 passwd 文件字段中的 x 表示加密密码存储在影子文件中(应在系统中进行配置)。星号 (*) 表示用户无法登录。
如果该密码字段为空白(即在一排中看到两个冒号,如::),则登录时不需要密码。请小心这样的空白密码。绝对不能让用户在没有密码的情况下登录。
其余的密码字段如下:
- 用户 ID(UID),即用户在内核中的代表。可以有两个用户 ID 相同的条目,但这样会让你感到困惑,也可能会让你的软件感到困惑,所以要保持用户 ID 的唯一性。
- 组 ID (GID),应该是 /etc/group 文件中的编号条目之一。组决定文件权限,除此之外几乎没有其他作用。该组也称为用户的主组。
-
- 用户的真实姓名(通常称为 GECOS 字段)。有时会在该字段中发现逗号,表示房间号和电话号码。
用户的主目录。
- 用户的真实姓名(通常称为 GECOS 字段)。有时会在该字段中发现逗号,表示房间号和电话号码。
- 用户的 shell(用户运行终端会话时运行的程序)。

/etc/passwd 文件语法相当严格,不允许有注释或空行。
注意:/etc/passwd 中的用户和相应的主目录统称为账户。不过,请记住这是用户空间的约定。通常只需在 passwd 文件中输入一个条目即可;大多数程序要识别一个账户,并不需要主目录的存在。此外,还有一些方法可以在系统中添加用户,而不需要明确地把他们写入 passwd 文件;例如,使用 NIS(网络信息服务)或 LDAP(轻量级目录访问协议)从网络服务器添加用户曾经很常见。
7.3.2 特殊用户
你会在 /etc/passwd 中发现一些特殊用户。超级用户(root)的 UID 始终为 0,GID 始终为 0,如清单 7-1 所示。某些用户,如 daemon,没有登录权限。nobody 用户是一个低权限用户;一些进程以 nobody 的身份运行,因为它(通常)不能写入系统中的任何内容。
不能登录的用户称为伪用户。虽然他们不能登录,但系统可以用他们的用户 ID 启动进程。伪用户(如 nobody)通常是出于安全考虑而创建的。
同样,这些都是用户空间的约定。这些用户对内核没有特殊意义;唯一对内核有特殊意义的用户 ID 是超级用户的 0。
7.3.3 /etc/shadow 文件
Linux 系统中的影子口令文件(/etc/shadow)通常包含用户身份验证信息,包括与 /etc/passwd 中的用户相对应的加密口令和口令过期信息。
引入影子文件是为了提供一种更灵活(或许也更安全)的密码存储方式。它包括一整套库和实用程序,其中许多很快就被 PAM(可插拔身份验证模块;我们将在第 7.10 节介绍这一高级主题)所取代。PAM 并没有为 Linux 引入一套全新的文件,而是使用 /etc/shadow,但不使用某些相应的配置文件,如 /etc/login.defs。
7.3.4 操作用户和密码
普通用户使用 passwd 命令和其他一些工具与 /etc/passwd 进行交互。使用 passwd 命令更改密码。你可以使用 chfn 和 chsh 分别更改真实姓名和 shell(shell 必须列在 /etc/shells 中)。这些都是 suid-root 可执行文件,因为只有超级用户才能更改 /etc/passwd 文件。
- 以超级用户身份更改 /etc/passwd
因为 /etc/passwd 只是一个普通的纯文本文件,所以从技术上讲,超级用户可以使用任何文本编辑器进行修改。要添加一个用户,只需添加一行适当的内容,并为该用户创建一个主目录即可;要删除一个用户,则可以反其道而行之。
不过,像这样直接编辑 passwd 并不是个好主意。这样做不仅容易出错,而且如果同时有其他东西在修改 passwd,还可能出现并发问题。通过终端或图形用户界面使用单独的命令对用户进行更改要容易得多(也安全得多)。例如,要设置用户密码,以超级用户身份运行 passwd user。使用 adduser 和 userdel 分别添加和删除用户。
不过,如果你真的必须直接编辑文件(例如,文件已损坏),请使用 vipw 程序,该程序会在你编辑 /etc/passwd 文件时备份并加锁,以防万一。要编辑 /etc/shadow 而不是 /etc/passwd,请使用 vipw -s。(希望你永远不需要使用这两种方法)。
7.3.5 使用组
Unix 中的组提供了一种在特定用户间共享文件的方法。其原理是为特定组设置读取或写入权限,将其他人排除在外。这一功能曾经非常重要,因为许多用户共享一台机器或网络,但近年来随着工作站的共享频率降低,这一功能的重要性也随之降低。
/etc/group 文件定义了组 ID(如 /etc/passwd 文件中的组 ID)。清单 7-2 是一个示例。
root:*:0:juser
daemon:*:1:
bin:*:2:
sys:*:3:
adm:*:4:
disk:*:6:juser,beazley
nogroup:*:65534:
user:*:1000:
清单 7-2: /etc/group 文件示例
与 /etc/passwd 文件一样,/etc/group 文件中的每一行都是一组用冒号分隔的字段。每个条目中的字段从左到右排列如下:
- 组名 在运行 ls -l 等命令时显示。
- 组密码 Unix 组密码几乎不使用,也不应该使用(在大多数情况下,sudo 是一个不错的选择)。使用 * 或其他默认值。这里的 x 表示 /etc/gshadow 中有相应的条目,而且几乎总是禁用密码,用 * 或 ! 表示。
- 组 ID(一个数字) GID 在组文件中必须是唯一的。这个数字会出现在用户 /etc/passwd 条目中的用户组字段中。
- 属于组的用户列表(可选) 除了此处列出的用户外,在其密码文件条目中具有相应组 ID 的用户也属于该组。

要查看所属组,请运行 groups。
注意:Linux 发行版通常会为每个新添加的用户创建一个新的组,组名与用户名相同。
7.4 getty和登录
getty 程序会连接到终端并显示登录提示。在大多数 Linux 系统中,getty 并不复杂,因为系统只用它在虚拟终端上登录。在进程列表中,它通常看起来像这样(例如,在 /dev/tty1 上运行时):
$ ps ao args | grep getty
/sbin/agetty -o -p -- \u --noclear tty1 linux
在许多系统上,你甚至可能看不到 getty 进程,直到你用 CTRL-ALT-F1 等命令访问虚拟终端。本例显示的是 agetty,许多 Linux 发行版都默认包含该版本。
输入登录名后,getty 会自动替换为登录程序,并要求输入密码。如果你输入了正确的密码,login 会(使用 exec())替换为你的 shell。否则,你将收到一条 “登录不正确 ”的信息。登录程序的大部分真正身份验证工作由 PAM 处理(参见第 7.10 节)。
注意:在研究 getty 时,你可能会遇到 “38400 ”这样的波特率。这种设置已经过时。虚拟终端会忽略波特率;波特率只用于连接真实串行线路。
你现在知道 getty 和 login 的作用了,但你可能永远不需要配置或更改它们。事实上,你甚至很少会用到它们,因为现在大多数用户都通过图形界面(如 gdm)或 SSH 远程登录,而这两种方式都不使用 getty 或 login。
7.5 设置时间
Unix 机器依赖于精确的计时。内核维护着系统时钟,当您运行 date 等命令时,系统时钟就会显示。您也可以使用 date 命令来设置系统时钟,但这样做通常不是个好主意,因为您永远无法精确地掌握时间。系统时钟应尽可能接近正确时间。
PC 硬件有一个电池支持的实时时钟(RTC)。RTC 并不是世界上最好的时钟,但有总比没有好。内核通常会在启动时根据 RTC 设置时间,你可以使用 hwclock 将系统时钟重置为当前的硬件时间。请将硬件时钟设置为世界协调时(UTC),以避免时区或夏令时校正带来的麻烦。您可以使用此命令将 RTC 设置为内核的 UTC 时钟:
# hwclock --systohc --utc
不幸的是,内核在计时方面比 RTC 更差,而且由于 Unix 机器在一次启动后往往要运行数月或数年,因此容易产生时间漂移。时间漂移是内核时间与真实时间(由原子钟或其他非常精确的时钟定义)之间的当前差值。
你不应该试图用 hwclock 来修复时间漂移,因为基于时间的系统事件可能会丢失或混淆。您可以运行类似 adjtimex 的实用程序,根据 RTC 平滑更新时钟,但通常最好使用网络时间守护进程(参见第 7.5.2 节)来保持系统时间的正确性。
7.5.1 内核时间表示和时区
内核的系统时钟将当前时间表示为自世界协调时 1970 年 1 月 1 日午夜 12:00 起的秒数。要查看当前时间,请运行
$ date +%s
为了将这一数字转换成人类可以读取的时间,用户空间程序会将其转换为本地时间,并对夏令时和其他奇怪的情况(例如居住在印第安纳州)进行补偿。本地时区由 /etc/localtime 文件控制。(别费劲去看它,这是一个二进制文件)。
系统中的时区文件位于 /usr/share/zoneinfo。你会发现该目录包含大量时区和时区别名。要手动设置系统的时区,要么将 /usr/share/zoneinfo 中的文件复制到 /etc/localtime(或建立符号链接),要么使用发行版的时区工具进行更改。命令行程序 tzselect 可以帮助你识别时区文件。
要在一次 shell 会话中使用系统默认时区以外的时区,可将 TZ 环境变量设置为 /usr/share/zoneinfo 中的文件名,然后测试更改,如下所示:
$ export TZ=US/Central
$ date
与其他环境变量一样,你也可以在单个命令的持续时间内设置时区,如下所示:
$ TZ=US/Central date
7.5.2 网络时间
如果机器与互联网永久连接,则可以运行网络时间协议 (NTP) 守护进程,通过远程服务器来维护时间。这曾由 ntpd 守护进程处理,但与许多其他服务一样,systemd 已用自己的软件包(名为 timesyncd)取代了它。大多数 Linux 发行版都包含 timesyncd,而且默认情况下已启用。你应该不需要对它进行配置,但如果你对如何配置感兴趣,timesyncd.conf(5) 手册页可以帮到你。最常见的覆盖是更改远程时间服务器。
如果想运行 ntpd,则需要禁用已安装的 timesyncd。请访问 https://www.ntppool.org/ 查看相关说明。如果你还想在不同的服务器上使用 timesyncd,这个网站也可能有用。
如果你的机器没有永久的互联网连接,可以使用 chronyd 等守护进程在断开连接时保持时间不变。
你也可以根据网络时间设置硬件时钟,以帮助系统在重启时保持时间一致性。许多发行版都会自动这样做,但要手动设置,请确保系统时间是通过网络设置的,然后运行以下命令:
# hwclock --systohc –-utc
7.6 使用cron和定时单位调度重复任务
有两种方法可以按重复计划运行程序:cron 和 systemd 定时器单元。这种能力对于自动执行系统维护任务至关重要。其中一个例子就是日志文件轮换实用程序,它可以确保硬盘不被旧日志文件填满(本章前面已经讨论过)。cron 服务一直以来都是实现这一目标的事实标准,我们将详细介绍它。不过,systemd 的定时器单元在某些情况下可以替代 cron,因此我们也将介绍如何使用它们。
你可以使用 cron 在任何适合你的时间运行任何程序。通过 cron 运行的程序称为 cron 作业。要安装 cron 作业,通常需要运行 crontab 命令,在 crontab 文件中创建一个入口行。例如,以下 crontab 文件条目将 /home/juser/bin/spmake 命令安排在每天上午 9:15(当地时区)运行:
15 09 * * * /home/juser/bin/spmake
该行开头的五个字段以空格分隔,指定了计划时间(另见图 7-3)。字段依次如下:
- 分钟(0 至 59)。此 cron 作业设置为第 15 分钟。
- 小时(0 至 23)。该任务设置为第 9 个小时。
- 月(1 至 31)。
- 月(1 到 12)。
- 星期(0 至 7)。数字 0 和 7 表示星期日。

任何字段中的星号 (*) 都表示匹配每个值。前面的示例每天都运行 spmake,因为月日、月和星期字段都填满了星,cron 将其理解为 “每月的每天、每周的每天都运行此任务”。
如果只在每月的第 14 天运行 spmake,可以使用以下 crontab 行:
15 09 14 * * /home/juser/bin/spmake
您可以为每个字段选择多个时间。例如,要在每月的第 5 天和第 14 天运行程序,可以在第三个字段中输入 5,14:
15 09 5,14 * * /home/juser/bin/spmake
注意:如果 cron 作业产生标准输出、错误或异常退出,cron 应将此信息通过电子邮件发送给 cron 作业的所有者(假设电子邮件在系统中正常工作)。如果觉得电子邮件令人讨厌,可将输出重定向到 /dev/null 或其他日志文件。
crontab(5) 手册页面提供了有关 crontab 格式的完整信息。
7.6.1 安装 Crontab 文件
每个用户都可以拥有自己的 crontab 文件,这意味着每个系统都可能有多个 crontab,通常位于 /var/spool/cron/crontabs。普通用户不能写入该目录;crontab 命令用于安装、列出、编辑和删除用户的 crontab。
安装 crontab 的最简单方法是将 crontab 条目放入一个文件,然后使用 crontab 文件将文件安装为当前的 crontab。crontab 命令会检查文件格式,确保没有任何错误。要列出 cron 作业,请运行 crontab -l。要删除 crontab,请使用 crontab -r。
创建初始 crontab 后,使用临时文件进行进一步编辑可能会有点乱。相反,您可以使用 crontab -e 命令一步完成 crontab 的编辑和安装。如果您犯了错误,crontab 会告诉您错误所在,并询问您是否要重新编辑。
7.6.2 系统 Crontab 文件
许多常见的 cron 激活的系统任务都是以超级用户身份运行的。不过,Linux 发行版通常会为整个系统设置一个 /etc/crontab 文件,而不是编辑和维护超级用户的 crontab 来安排这些任务。你不会用 crontab 来编辑这个文件,而且在任何情况下,它的格式都略有不同:在要运行的命令之前,有一个额外的字段指定了应该运行作业的用户。(这让你有机会将系统任务分组,即使它们并非都由同一用户运行)。例如,在 /etc/crontab 中定义的 cron 作业以超级用户(root 1)身份在早上 6:42 运行:
42 6 * * * root1 /usr/local/bin/cleansystem > /dev/null 2>&1
注意:某些发行版会在 /etc/cron.d 目录中存储额外的系统 crontab 文件。这些文件可以有任何名称,但格式与 /etc/crontab 相同。可能还有一些目录,如 /etc/cron.daily,但这里的文件通常是由 /etc/crontab 或 /etc/cron.d 中特定 cron 作业运行的脚本。
7.6.3 定时器单元
为定期任务创建 cron 作业的另一种方法是创建 systemd 定时器单元。对于一个全新的任务,必须创建两个单元:一个计时器单元和一个服务单元。之所以要创建两个单元,是因为定时器单元并不包含要执行任务的任何细节;它只是运行服务单元(或概念上的另一种单元,但最常用的是服务单元)的激活机制。
让我们从定时器单元开始,看看一对典型的定时器/服务单元。我们将其称为 loggertest.timer;与其他自定义单元文件一样,我们将其放在/etc/systemd/system 中(见清单 7-3)。
[Unit]
Description=Example timer unit
[Timer]
OnCalendar=*-*-* *:00,20,40
Unit=loggertest.service
[Install]
WantedBy=timers.target
此计时器每 20 分钟运行一次,OnCalendar 选项与 cron 语法相似。在此示例中,它在每小时的顶部以及每小时过去 20 分钟和 40 分钟时运行。
OnCalendar 的时间格式为年-月-日-时:分:秒。秒字段是可选的。与 cron 一样,* 表示通配符,逗号允许多个值。周期/语法也有效;在前面的示例中,可以将 *:00,20,40 改为 *:00/20(每 20 分钟),以达到同样的效果。
注意OnCalendar 字段中的时间语法有很多快捷方式和变化。有关完整列表,请参阅 systemd.time(7) 手册页面的日历事件部分。
相关服务单元名为 loggertest.service(见清单 7-4)。我们在定时器中使用 Unit 选项明确命名了它,但这并非严格必要,因为 systemd 会查找与定时器单元文件基本名称相同的 .service 文件。该服务单元也放在 /etc/systemd/system 中,与第 6 章中的服务单元非常相似。
[Unit]
Description=Example Test Service
[Service]
Type=oneshot
ExecStart=/usr/bin/logger -p local3.debug I\'m a logger
其中最重要的是 ExecStart 这一行,它是服务激活时运行的命令。本例将向系统日志发送一条信息。
请注意,服务类型使用了 oneshot,这表明服务将运行并退出,在 ExecStart 指定的命令完成之前,systemd 不会认为服务已启动。这对定时器有一些好处:
你可以在单元文件中指定多个 ExecStart 命令。我们在第 6 章中看到的其他服务单元样式不允许这样做。
使用 Wants 和 Before 依赖关系指令激活其他单元时,更容易控制严格的依赖关系顺序。
您可以在日志中更好地记录单元的开始和结束时间。
在本单元示例中,我们使用日志记录器向系统日志和日志发送条目。在第 7.1.2 节中,您可以按单元查看日志信息。不过,单元可能会在 journald 接收到消息之前结束。这是一个竞赛条件,如果单元完成得太快,journald 将无法查找与 syslog 消息相关的单元(通过进程 ID 查找)。因此,写入日志的信息可能不包含单元字段,导致 journalctl -f -u loggertest.service 等过滤命令无法显示系统日志信息。这在运行时间较长的服务中通常不是问题。
7.6.4 cron与定时器单位
cron 实用程序是 Linux 系统中最古老的组件之一;它已经存在了几十年(比 Linux 本身还要早),其配置格式多年来一直没有太大变化。当一个东西变得如此老旧时,它就成了被替换的对象。
你刚才看到的 systemd 定时器单元似乎是一个合乎逻辑的替代品,事实上,许多发行版现在已经将系统级的定期维护任务转移到了定时器单元上。但事实证明,cron 也有一些优势:
- 配置更简单
- 与许多第三方服务兼容
- 用户更容易安装自己的任务
定时器单元具有以下优势
- 可通过 cgroups 跟踪与任务/单元相关的进程
- 可在日志中跟踪诊断信息
- 激活时间和频率的额外选项
- 可使用 systemd 依赖关系和激活机制
也许有一天,cron 作业也能像挂载单元和 /etc/fstab 一样,拥有一个兼容层。不过,仅配置这一点就足以说明 cron 格式不可能在短期内消失。正如你将在下一节看到的那样,一个名为 systemd-run 的实用程序的确可以在不创建单元文件的情况下创建定时器单元和相关服务,但其管理和实现方式的差异足以让许多用户倾向于使用 cron。我们将在下一节中讨论这一点。
7.7 使用 at 调度一次性任务
要在未来运行一次作业而不使用 cron,可使用 at 服务。例如,要在晚上 10:30 运行 myjob,请输入以下命令:
$ at 22:30
at> myjob
用 CTRL-D 结束输入。(at 工具从标准输入中读取命令)。
要检查作业是否已调度,请使用 atq。要删除作业,请使用 atrm。还可以通过添加 DD.MM.YY 格式的日期来安排未来几天的工作,例如,22:30 30.09.15。
at 命令的其他功能不多。虽然它并不常用,但在需要时却非常有用。
7.7.1 定时器单位等价物
你可以使用 systemd 定时器单位来替代 at。这些定时器单元比前面提到的周期性定时器单元更容易创建,可以像下面这样在命令行上运行:
# systemd-run --on-calendar='2022-08-14 18:00' /bin/echo this is a test
Running timer as unit: run-rbd000cc6ee6f45b69cb87ca0839c12de.timer
Will run service as unit: run-rbd000cc6ee6f45b69cb87ca0839c12de.service
systemd-run 命令会创建一个瞬时定时器单元,你可以使用常用的 systemctl list-timers 命令查看该单元。如果不关心具体时间,可以使用 --on-active 指定一个时间偏移(例如,--on-active=30m 表示未来 30 分钟)。
注意使用 --on-on-calendar 时,除了时间外,还必须包含(未来)日历日期。否则,定时器和服务单元将保持不变,定时器每天在指定时间运行服务,就像前面描述的创建普通定时器单元一样。该选项的语法与定时器单元中的 OnCalendar 选项相同。
7.8 作为普通用户运行的定时器单元
到目前为止,我们看到的所有 systemd 定时器单元都是以 root 用户身份运行的。以普通用户身份创建定时器单元也是可行的。为此,请在 systemd-run 中添加 --user 选项。
不过,如果在单元运行前注销,单元将无法启动;如果在单元完成前注销,单元将终止。出现这种情况是因为 systemd 有一个与登录用户相关联的用户管理器,而这是运行定时器单元所必需的。您可以使用以下命令让 systemd 在您注销后保留用户管理器:
$ loginctl enable-linger
以 root 用户身份,也可以为其他用户启用管理器:
# loginctl enable-linger user
7.9 用户访问主题
本章余下部分将介绍用户如何获得登录权限、切换到其他用户以及执行其他相关任务。这部分内容有些高深,如果你已经准备好接触一些进程内部知识,欢迎跳到下一章。
7.9.1 用户 ID 和用户切换
我们已经讨论过 sudo 和 su 等 setuid 程序如何允许你临时更改用户,也介绍过登录等控制用户访问的系统组件。也许你想知道这些组件是如何工作的,以及内核在用户切换中扮演了什么角色。
当你临时切换到另一个用户时,你所做的其实就是改变你的用户 ID。有两种方法可以做到这一点,内核都会处理。第一种是使用 setuid 可执行文件,这在第 2.17 节中已有介绍。第二种是通过 setuid() 系列系统调用。该系统调用有几个不同的版本,以适应与进程相关的各种用户 ID,这将在第 7.9.2 节中介绍。
内核有关于进程能做什么或不能做什么的基本规则,但以下三个要点涵盖了 setuid 可执行文件和 setuid():
- 只要有足够的文件权限,进程就可以运行 setuid 可执行文件。
- 以根用户(用户 ID 0)身份运行的进程可以使用 setuid() 变成任何其他用户。
- 以非 root 用户身份运行的进程在如何使用 setuid() 方面受到严格限制;在大多数情况下,它不能使用 setuid()。
由于存在这些规则,如果要将用户 ID 从普通用户切换到其他用户,通常需要结合使用多种方法。例如,sudo 可执行文件是 setuid root,一旦运行,它就可以调用 setuid() 成为另一个用户。
注意:用户切换的核心与密码或用户名无关。正如你在第 7.3.1 节的 /etc/passwd 文件中第一次看到的那样,这些都是严格意义上的用户空间概念。你将在第 7.9.4 节中了解更多有关其工作原理的细节。
7.9.2 进程所有权、有效 UID、真实 UID 和保存 UID
到目前为止,我们对用户 ID 的讨论已经简化。实际上,每个进程都有一个以上的用户 ID。到目前为止,大家已经熟悉了有效用户 ID(有效 UID 或 euid),它定义了进程的访问权限(最重要的是文件权限)。第二个用户 ID,即真实用户 ID(real UID,或 ruid),表示进程由谁启动。通常情况下,这些ID是相同的,但当你运行一个setuid程序时,Linux会在执行过程中将euid设置为程序的所有者,但会在ruid中保留你原来的用户ID。
有效用户 ID 和真实用户 ID 之间的区别很容易混淆,以至于很多关于进程所有权的文档都是错误的。
把 euid 看作行为者,把 ruid 看作所有者。ruid 定义了可以与运行中的进程交互的用户--最重要的是,哪个用户可以杀死进程并向其发送信号。例如,如果用户 A 启动了一个新进程,该进程以用户 B 的身份运行(基于 setuid 权限),那么用户 A 仍然拥有该进程,并可以杀死它。
我们已经看到,大多数进程都有相同的 euid 和 ruid。因此,ps 和其他系统诊断程序的默认输出只显示 euid。要查看系统中的两个用户 ID,请试试下面的方法,但如果发现系统中所有进程的两个用户 ID 列都相同,也不要惊讶:
$ ps -eo pid,euser,ruser,comm
要想制造一个异常,以便在列中看到不同的值,可以尝试创建一个 sleep 命令的 setuid 副本,运行该副本几秒钟,然后在副本终止前在另一个窗口中运行前面的 ps 命令。
除了真实和有效的用户 ID 外,还有一个保存的用户 ID(通常不是缩写),这就更令人困惑了。进程可以在执行过程中将其 euid 切换为 ruid 或保存的用户 ID。(让事情变得更复杂的是,Linux 还有另一个用户 ID:文件系统用户 ID 或 fsuid,它定义了访问文件系统的用户,但很少使用)。
- 典型的 Setuid 程序行为
ruid 的概念可能与你以前的经验相矛盾。为什么你不需要经常处理其他用户 ID 呢?例如,用 sudo 启动一个进程后,如果要杀死它,仍然要使用 sudo,而不能用自己的普通用户杀死它。在这种情况下,你的普通用户不应该是 ruid 吗?
造成这种行为的原因是,sudo 和许多其他 setuid 程序通过 setuid() 系统调用之一明确更改了 euid 和 ruid。这些程序之所以这样做,是因为当所有用户 ID 不匹配时,往往会产生意想不到的副作用和访问问题。
注意:如果你对用户 ID 切换的细节和规则感兴趣,请阅读 setuid(2) 手册页面,并查看 SEE ALSO 部分列出的其他手册页面。有许多不同的系统调用适用于不同的情况。
有些程序不喜欢使用 root 的 ruid。为防止 sudo 更改 ruid,请在 /etc/sudoers 文件中添加此行(小心会对你想以 root 身份运行的其他程序产生副作用!):
Defaults stay_setuid
- 安全问题
由于 Linux 内核通过 setuid 程序和随后的系统调用来处理所有用户开关(以及文件访问权限),因此系统开发人员和管理员必须对两件事格外小心:拥有 setuid 权限的程序的数量和质量;这些程序会做什么。
如果你复制了一个设置为 root 的 bash shell,那么任何本地用户都可以执行它并完全运行系统。就是这么简单。此外,即使是设置为 “root ”用户的特殊用途程序,如果存在漏洞,也会带来危险。利用以 root 身份运行的程序中的弱点是入侵系统的主要方法,此类漏洞数不胜数。
由于入侵系统的方法如此之多,因此防止入侵是一件多方面的事情。防止不必要的活动进入系统的最基本方法之一是使用用户名和密码进行用户身份验证。
7.9.3 用户识别、身份验证和授权
多用户系统必须在三个方面为用户安全提供基本支持:识别、验证和授权。安全的识别部分回答了用户是谁的问题。身份验证部分要求用户证明自己的身份。最后,授权用于定义和限制用户的权限。
说到用户身份验证,Linux 内核只知道进程和文件所有权的数字用户 ID。内核知道如何运行setuid可执行文件的授权规则,以及用户ID如何运行setuid()系列系统调用来从一个用户变为另一个用户。但是,内核对身份验证(用户名、密码等)一无所知。实际上,与身份验证有关的一切都发生在用户空间。
我们在第 7.3.1 节中讨论了用户 ID 和密码之间的映射,现在我们将讨论用户进程如何访问这一映射。我们将从一个过于简单的情况开始,即用户进程想知道自己的用户名(与 euid 对应的名称)。在传统的 Unix 系统中,进程可以这样获取用户名:
- 进程使用 geteuid() 系统调用向内核询问其 euid。
- 进程打开 /etc/passwd 文件并从头开始读取。
- 进程读取 /etc/passwd 文件中的一行。如果没有可读取的内容,则说明进程未能找到用户名。
- 进程会将这一行解析为多个字段(将冒号之间的所有内容分隔开来)。第三个字段是当前行的用户 ID。
- 进程会将步骤 4 中的 ID 与步骤 1 中的 ID 进行比较。如果两者相同,则步骤 4 中的第一个字段就是所需的用户名,进程可以停止搜索并使用该名称。
- 进程将进入 /etc/passwd 中的下一行,并返回第 3 步。
这是一个很长的过程,实际执行起来通常更加复杂。
7.9.4 使用库获取用户信息
如果每个需要知道当前用户名的开发人员都必须编写刚才所看到的所有代码,那么系统就会变得杂乱无章、漏洞百出、臃肿不堪、无法维护。幸运的是,我们通常可以使用标准库来执行类似的重复性任务;在这种情况下,通常只需在得到 geteuid() 的答案后调用标准库中的 getpwuid() 函数即可获得用户名。(有关这些调用的工作原理,请参阅相关手册)。
系统中的可执行文件共享标准库,因此你可以在不更改任何程序的情况下对身份验证实现进行重大修改。例如,只需更改系统配置,就可以不再使用 /etc/passwd 访问用户,而是使用 LDAP 等网络服务。
这种方法在识别与用户 ID 相关联的用户名时效果很好,但密码则比较麻烦。第 7.3.1 节介绍了传统上如何将加密密码作为 /etc/passwd 文件的一部分,因此如果要验证用户输入的密码,就需要加密用户输入的内容,然后与 /etc/passwd 文件的内容进行比较。
这种传统的实现方式有很多局限性,包括
- 无法为加密协议设定全系统标准。
- 它假定你可以访问加密密码。
- 假定每次用户要访问需要身份验证的内容时,都要提示用户输入密码(这很烦人)。
- 假设你想使用密码。如果你想使用一次性令牌、智能卡、生物识别或其他形式的用户身份验证,就必须自己添加支持。
第 7.3.3 节中讨论的影子口令软件包的开发就受到了其中一些限制,它在允许全系统口令配置方面迈出了第一步。但是,PAM 的设计和实施解决了大部分问题。
7.10 可插拔身份验证模块
为了适应用户身份验证的灵活性,1995 年,Sun Microsystems 公司提出了一个新的标准,称为可插拔身份验证模块(PAM Pluggable Authentication Modules),这是一个用于身份验证的共享库系统(开放软件基金会 RFC 86.0,1995 年 10 月)。要对用户进行身份验证,应用程序会将用户交给 PAM,以确定用户是否能成功识别自己。这样,就可以相对容易地添加对其他身份验证技术(如双因素和物理密钥)的支持。除了支持身份验证机制,PAM 还为服务提供了有限的授权控制(例如,如果你想拒绝向某些用户提供 cron 等服务)。
由于存在多种身份验证情况,PAM 采用了大量可动态加载的身份验证模块。每个模块都执行特定的任务,是一个共享对象,进程可以动态加载并在其可执行空间中运行。例如,pam_unix.so 就是一个可以检查用户密码的模块。
至少可以说,这是一项棘手的工作。编程界面并不简单,而且 PAM 是否真的能解决现有的所有问题也不清楚。不过,几乎所有需要在 Linux 系统上进行身份验证的程序都支持 PAM,而且大多数发行版都使用 PAM。由于 PAM 是在现有的 Unix 身份验证 API 的基础上工作的,因此将支持集成到客户端几乎不需要任何额外的工作。
7.10.1 PAM 配置
我们将通过检查 PAM 的配置来了解其基本工作原理。PAM 的应用程序配置文件通常位于 /etc/pam.d 目录中(旧系统可能只使用一个 /etc/pam.conf 文件)。大多数安装文件都包含许多文件,因此您可能不知道从哪里开始。有些文件名(如 cron 和 passwd)与您已经知道的系统部分相对应。
由于不同发行版中这些文件的具体配置差异很大,因此很难找到一个普遍适用的示例。我们来看看 chsh(更改 shell 程序)的配置行示例:
auth requisite pam_shells.so
这一行说明,用户的 shell 必须列在 /etc/shells 中,这样用户才能成功通过 chsh 程序的身份验证。让我们看看是如何做到的。每一行配置都有三个字段:依次是函数类型、控制参数和模块。下面是它们在本例中的含义:
- 功能类型 用户应用程序要求 PAM 执行的功能。这里是 auth,即验证用户身份的任务。
- 控制参数 该设置控制 PAM 在当前行(本例中为必要条件)的操作成功或失败后的操作。我们很快就会讨论这个问题。
- 模块 该行运行的身份验证模块,决定该行的实际操作。在这里,pam_shells.so 模块会检查用户当前的 shell 是否列在 /etc/shells 中。
- PAM 配置详见 pam.conf(5) 手册页面。让我们来看看其中的一些要点。
用户应用程序可以要求 PAM 执行以下四种功能之一:
- auth 验证用户(查看用户身份)。
- account 检查用户账户状态(例如,用户是否被授权做某事)。
- session 仅对用户当前会话执行某些操作(如显示每日信息)。
- password 更改用户密码或其他凭证。
对于任何配置行,模块和功能共同决定 PAM 的操作。一个模块可以有多个功能类型,因此在确定配置行的目的时,请务必将功能和模块视为一对。例如,pam_unix.so 模块在执行 auth 功能时会检查密码,但在执行 password 功能时会设置密码。
控制参数和堆叠规则
PAM 的一个重要特性是其配置行指定的规则可以堆叠,这意味着在执行一个功能时可以应用多个规则。这也是控制参数非常重要的原因:一行操作的成功或失败会影响后续行,或导致整个函数的成功或失败。
控制参数有两种:简单语法和更高级的语法。以下是规则中的三种主要简单语法控制参数:
sufficient 如果该规则成功,则身份验证成功,PAM 无需查看其他规则。如果规则失败,PAM 将继续查看其他规则。
必要条件 如果该规则成功,PAM 将继续执行其他规则。如果该规则失败,则身份验证不成功,PAM 无需查看更多规则。
required 如果此规则成功,PAM 将转到其他规则。如果该规则失败,PAM 会继续执行其他规则,但无论其他规则的最终结果如何,PAM 都会返回身份验证不成功。
继续前面的示例,下面是 chsh 身份验证函数的堆栈示例:
auth sufficient pam_rootok.so
auth requisite pam_shells.so
auth sufficient pam_unix.so
auth required pam_deny.so
在此配置下,当 chsh 命令要求 PAM 执行身份验证功能时,PAM 会执行以下操作(流程图见图 7-4):
pam_rootok.so 模块会检查 root 是否是试图进行身份验证的用户。如果是,则立即成功,不再尝试其他身份验证。这是因为控制参数被设置为 sufficient,这意味着该操作成功后,PAM 会立即向 chsh 报告成功。否则,将继续执行步骤 2。
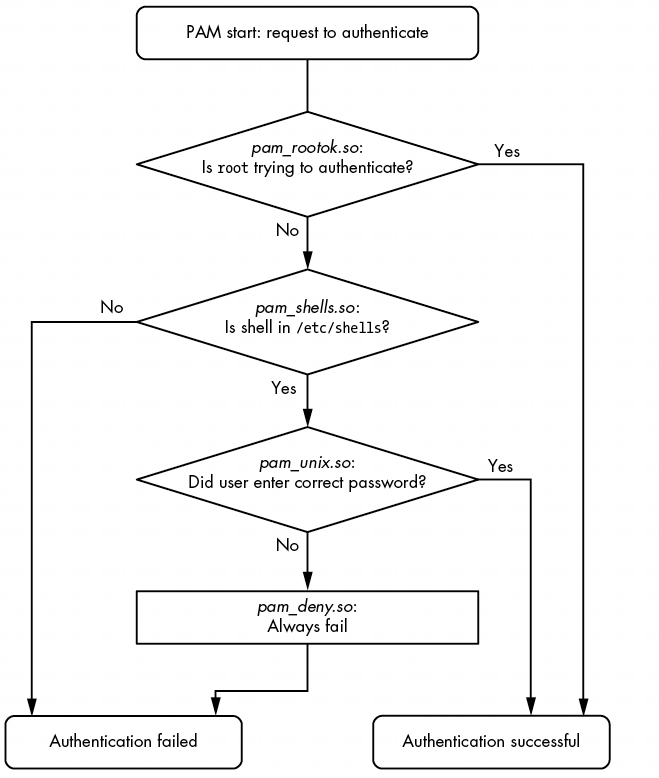
pam_shells.so 模块会检查 /etc/shells 中是否列出了用户的 shell。如果没有,模块将返回失败,必要的控制参数表示 PAM 必须立即将此失败报告给 chsh,并不再尝试进一步的身份验证。否则,模块将返回成功,并执行 requisite 控制标志;继续执行第 3 步。
pam_unix.so 模块会询问用户密码并进行检查。控制参数设置为 sufficient,因此只要该模块成功(密码正确),PAM 就会向 chsh 报告成功。如果密码不正确,PAM 会继续执行第 4 步。
pam_deny.so 模块总是失败,由于控制参数被设置为 required,PAM 会向 chsh 报告失败。这是一个默认设置,用于在没有任何尝试的情况下。(请注意,必填控制参数并不会导致 PAM 的函数立即失败--它会运行堆栈中剩余的任何行,但 PAM 始终会向应用程序报告失败)。
注意
在使用 PAM 时,不要混淆功能和操作这两个术语。功能是高层次的目标:用户应用程序希望 PAM 做什么(例如,验证用户身份)。操作是 PAM 为实现该目标而采取的具体步骤。请记住,用户应用程序首先调用函数,而 PAM 则负责操作的具体细节。
方括号([])内的高级控制参数语法允许您根据模块的特定返回值(而不仅仅是成功或失败)手动控制反应。有关详情,请参阅 pam.conf(5) 手册页面;理解了简单语法后,使用高级语法就不会有问题了。
PAM 模块可以在模块名后面加上参数。你经常会在 pam_unix.so 模块中遇到这个例子:
auth sufficient pam_unix.so nullok
这里的 nullok 参数表示用户可以没有密码(如果用户没有密码,默认情况下会失败)。
7.10.2 PAM 配置语法提示
由于其控制流能力和模块参数语法,PAM 配置语法具有许多编程语言的特性和一定的功能。到目前为止,我们只是浅尝辄止,但这里还有一些关于 PAM 的提示:
要想知道系统中存在哪些 PAM 模块,请尝试使用 man -k pam_(注意下划线)。查找模块的位置可能比较困难。试试 locate pam_unix.so 命令,看看会指向哪里。
手册页面包含每个模块的功能和参数。
许多发行版会自动生成特定的 PAM 配置文件,因此直接在 /etc/pam.d 中修改这些文件可能并不明智。
/etc/pam.d/other配置文件为没有自己配置文件的应用程序定义了默认配置。默认配置通常是拒绝一切。
在 PAM 配置文件中包含附加配置文件有多种方法。@include 语法会加载整个配置文件,但也可以使用控制参数只加载特定功能的配置。不同发行版的用法有所不同。
PAM 配置并不以模块参数结束。某些模块可以访问 /etc/security 中的附加文件,通常用于配置对每个用户的限制。
7.10.3 PAM 和密码
由于 Linux 密码验证多年来的演变,有许多密码配置工具有时会造成混乱。首先要注意的是 /etc/login.defs 文件。这是原始影子密码套件的配置文件。它包含了 /etc/shadow 密码文件所用加密算法的信息,但在安装了 PAM 的系统中很少使用,因为 PAM 配置中包含了这些信息。因此,在遇到不支持 PAM 的应用程序时,/etc/login.defs 中的加密算法应与 PAM 配置相匹配。
PAM 从哪里获取密码加密方案的信息?请记住,PAM 有两种与密码交互的方式:auth 函数(用于验证密码)和 password 函数(用于设置密码)。追踪密码设置参数是最简单的方法。最好的方法可能就是用 grep 搜索:
$ grep password.*unix /etc/pam.d/*
password sufficient pam_unix.so obscure sha512
参数 obscure 和 sha512 告诉 PAM 在设置密码时要做什么。首先,PAM 会检查密码是否足够 “晦涩”(即密码与旧密码不太相似等),然后 PAM 会使用 SHA512 算法对新密码进行加密。
但这只会在用户设置密码时发生,而不会在 PAM 验证密码时发生。那么,PAM 如何知道在验证时使用哪种算法呢?不幸的是,配置文件不会告诉你任何信息;pam_unix.so 的 auth 函数没有加密参数。手册页面也什么都没告诉你。
事实证明(截至本文撰写时),pam_unix.so 只是试图猜测算法,通常会要求 libcrypt 库做一些脏活累活,尝试一大堆东西,直到有东西能用或没有东西可试为止。因此,您通常不必担心验证加密算法。
7.11 展望未来
我们现在正处于本书的中点,已经涵盖了 Linux 系统的许多重要组成部分。关于 Linux 系统日志和用户的讨论向你展示了如何将服务和任务划分为独立的小块,并在一定程度上进行交互。
本章几乎只讨论了用户空间,现在我们需要完善我们对用户空间进程及其所消耗资源的看法。为此,我们将在第 8 章回到内核。
热门相关:废材逆袭:冰山王爷倾城妃 纨绔毒医 天命为妃 超级融合 神话版三国