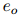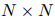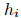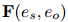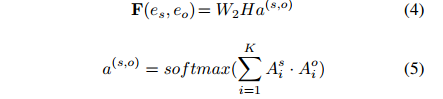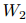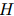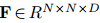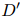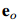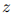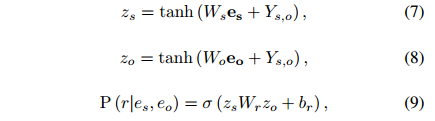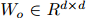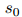为了捕获文档中多个三元组的相互依赖关系,本文将文档级关系抽取任务转化为一种实体级的分类问题[Jiang et al., 2019],也叫做表格填充[Miwa and Sasaki, 2014; Gupta et al., 2016],如图2所示。这种问题类似于语义分割(一个广泛应用的计算机视觉任务),它的目标是用卷积网络给图像的每个像素分配一个对应的类别标签。受此启发,本文提出了一种新颖的模型,名为文档U形网络(DocuNet),它将文档级关系抽取建模为语义分割问题。在这个模型中,本文将实体对之间的相关特征作为图像输入,然后预测每个实体对的关系类型作为像素级的输出。具体来说,本文设计了一个编码器模块来获取实体的上下文信息,以及一个U形分割模块来获取三元组之间的全局依赖信息。本文还提出了一种平衡的softmax方法来处理关系类别的不平衡分布。本文的主要贡献有以下几点:
首次将文档级关系抽取问题建模为语义分割问题。
提出了模型DocuNet,它能够有效地捕获文档级关系抽取的局部和全局信息。
在三个公开的数据集上进行了实验,证明了本文模型相比于现有的方法有显著的性能提升。
2 Related Work
一方面,本文受到了[Jin et al., 2020]的启发,他们是首次考虑关系之间全局交互的研究,而这方面的研究还很少见。另一方面,本文注意到卷积神经网络(CNN)在关系抽取(RE)领域已经有了很多应用,这些研究[Nguyen and Grishman, 2015; Shen and Huang, 2016]表明CNN可以有效地提取图像风格的特征图。因此,本文的工作也与[Liu et al., 2020]的研究有关,他们将不完整的话语重写视为一种语义分割任务,这激发了本文从计算机视觉的角度来探索RE问题。本文采用了U-Net [Ronneberger et al., 2015],它由一个收缩路径和一个对称的扩展路径组成,分别用于捕获上下文信息和实现精确的定位。据本文所知,这是第一次将RE问题建模为语义分割任务。